SIA: Swarm Intelligence Algorithms
الگوریتم های هوش جمعیSIA: Swarm Intelligence Algorithms
الگوریتم های هوش جمعی
چگونگی ارزیابی نتایج الگوریتمهای هیوریستیک در مقالات علمی
در این پست نکاتی برای ارائه نتایج مقالات علمی در مجلات معتبر بیانمیشود تا به کمک این نکات بتوان مقاله علمی مناسبتر و قویتری برای ژورنالها ارسالکرد. بدین منظور از مواردی که در برخی از مقالات در ژورنالهای معتبر به چاپ رسیده، بهرهبرداریشدهاست. در ادامه به پنج نکته مهم از این موارد، اشارهمیشود:
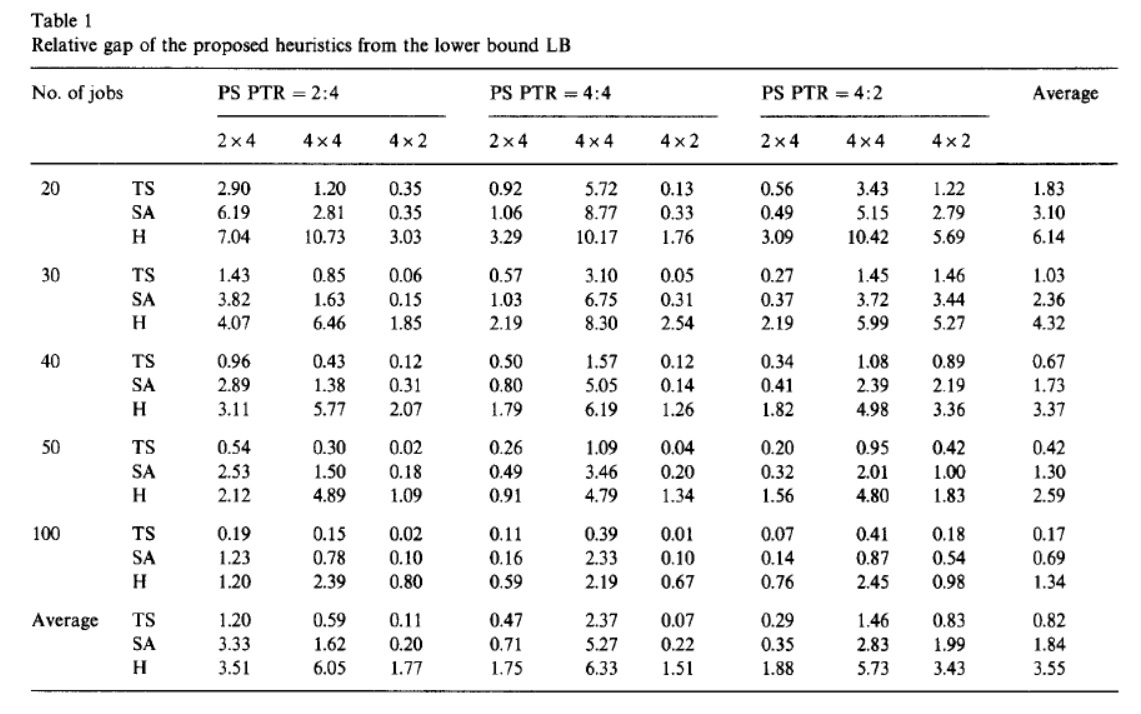
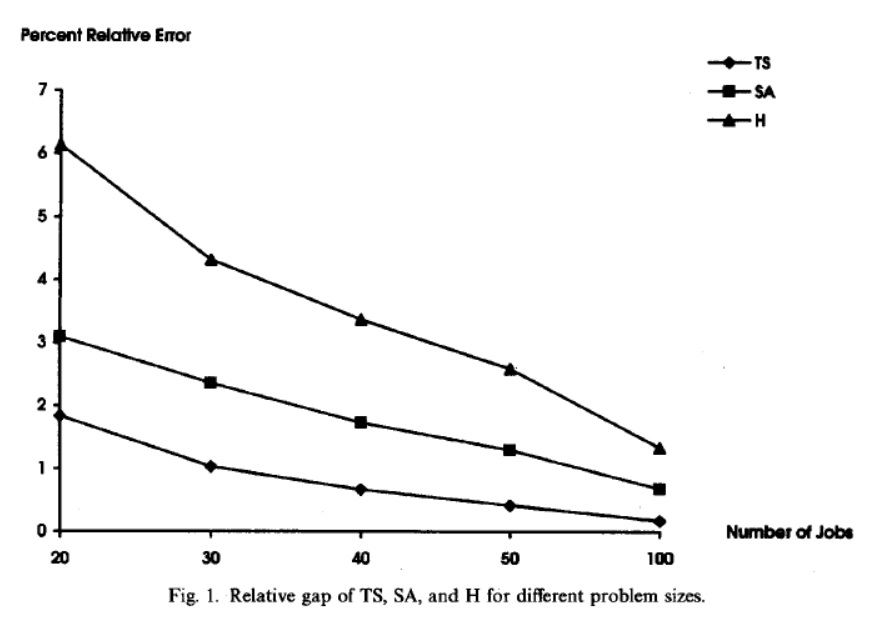
نکته اول: چینش پارمترها، نام مسائل و اندازههای مختلف مسئله در جدول میتواند در شفافسازی ارزیابی نتایج کمککند. همچنین در ترسیم نمودار برای ارزیابی نتایج انتخاب پارامترهای دو محور افقی و عمودی، ابعاد محورها و انتخاب نوع ترسیم نمودار به این شفافیت کمک شایانیمیکند. به طور مثال در مقاله [1] که الگوریتم های ابتکاری برای مسئله جریان کارگاهی (Flowshop) ترکیبی دو مرحلهای ارائهشده است در Table 1 آن الگوریتم های مختلف به همزاه الگوریتم پیشنهادی نرخ زمان پردازش برای کارهای با اندازه 20،30،40،50 و 100 موردمقایسه قرارگرفتهاست. در ستون و سطر آخر نیز میانگین زمان اجرا هر روش با توجه به اندازه مسئله، نشاندادهشدهاست. همچین در Figure1 این مقاله نرخ خطا براساس اندازه مسئله به نمایشدرآمدهاست.
نکته دوم: استفاده از آزمون ویلکاکسون رتبههای علامتدار میتواند تست خوبی برای ارزیابی دو نمونه وابسته باشد. در اینجا هدف از آزمون فرض آماری مشخصکردن تفاوت بین دو زوجهاست( ترکیبی از یک داده از هر نمونه زوج، تشکیلمیشود). «فرض صفر» نشان از یکسان بودن دادههای زوج است و «فرض مقابل» هم وجود اختلاف بین مقادیر دو نمونه در زوج را نشانمیدهد. تفاضل بین دو مقدار هر زوج علامت آن را نشانمیدهد. در واقع sign یا علامت مثبت باشد تابع علامت مقدار یک میگیرد و اگر علامت منفیباشد تابع علامت مقدار-1 میگیرد. در این آزمون از آماره W استفادهمیشود:
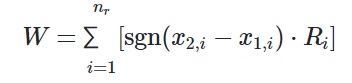
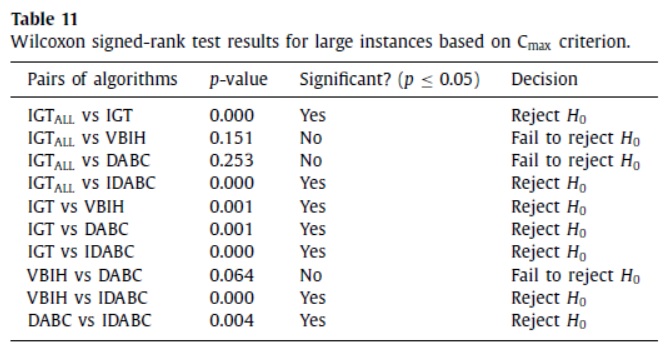
که در آن Ri رتبه اختلاف برای زوج iام است. حال، این آماره W با جدول آماره W مقایسهمیشود، اگر بزرگتر باشد یعنی در ناحیه بحرانی نیست و «فرض صفر» رد نمیشود و در نتیجه یکسانبودن مقادیر اول و دوم زوج های نمونه رد نمیشود. به طور مثال در مقاله [2] الگوریتمهای فراابتکاری برای مسئله زمانبدی جریان کارگاهی ترکیبی ارائهشدهاست که در Table 11 آن آزمون ویلکاکسون رتبههای علامتدار برای نمونههای بزرگ مبتنی بر معیار Cmax برای زوج الگوریتمهای مختلف با یکدیگر مورد مقایسه قرارگرفتهاند. در جاهایی که p-value<0.05 میباشد یعنی در ناحیه بحرانی قراردارد و اختلاف معناداری بین دو مقدار نمونه وجود دارد. و «فرض صفر» ردمیشود. یعنی این دو مقدار از زوجها با یکدیگر یکسان نمیباشند(Reject H0). اگر دو مقدار زوج ها اختلاف معناداری با یکدیگر نداشته باشند یعنی در ناحیه بحرانی نمیباشند و «فرض صفر» رد نمیشود (Fail to reject H0). در واقع، یکسان بودن دو مقدار زوجهای دو نمونه رد نمیشود.
نکته سوم: یکی از پارامترهای مهم دیگری که در بررسی میزان همگرائی راه حل الگوریتمهای فراابتکاری مهم است، نحوه رفتار جستجو (Search Behavior) الگوریتمهای فراابتکاری است. این رفتار باید به طور پویا، ارزیابیشود. برای هر الگوریتم فراابتکاری، محاسبه این رفتار جستجو متفاوت است. به طور مثال برای الگوریتم ژنتیک میتوان این رفتار را روی عملگرهای تقاطع و جهش انجامداد و یا اینکه در مرجع [3] رفتار جستجو الگوریتم هارمونی به صورت پویا در Relation 3 آن به صورت زیر مورد ارزیابی قرارگرفتهاست:

که در آن D ابعاد حافظه هارمونیو VAR(HMi) نشاندهنده واریانس هر بعد است.
نکته چهارم: به منظور تشخیص اختلاف معناداری دو الگوریتم، میتوان از آزمون t-test استفادهکرد. بدین منظور از فرمول زیر برای بدست آوردن مقدار t استفادهمیشود:
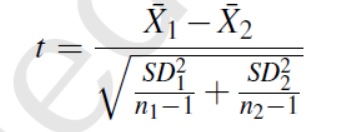
که در آن منظور از X1,SD1,n1 به ترتیب میانگین، انحراف معیار استاندارد و اندازه نمونه اول و X2,SD2,n2 نیز به ترتیب میانگین، انحراف معیار استاندارد و اندازه برای نمونه دوم است. مقدار t-value میتواند مثبت یا منفی باشد. مثبتبودن یعنی نمونه دوم و منفی یعنی نمونه اول راه حل بهتری برای بهینهسازی دارد. اگر سطح اطمینان 95% باشد به معنی این است که t0.05=1.96 است( این مقدار به کمک جدول احتمال تجمعی متغیر تصادفی نرمال استاندارد بدست می آید و فاصله اطمینان از فرمول بدستمیآید). حال اگر مقدار t>1.96 باشد آنگاه نمونه دوم بهتر از نمونه اول می باشد و اگر t<-1.96 باشد آنگاه نمونه اول بهتر از نمونه دوم است[4].
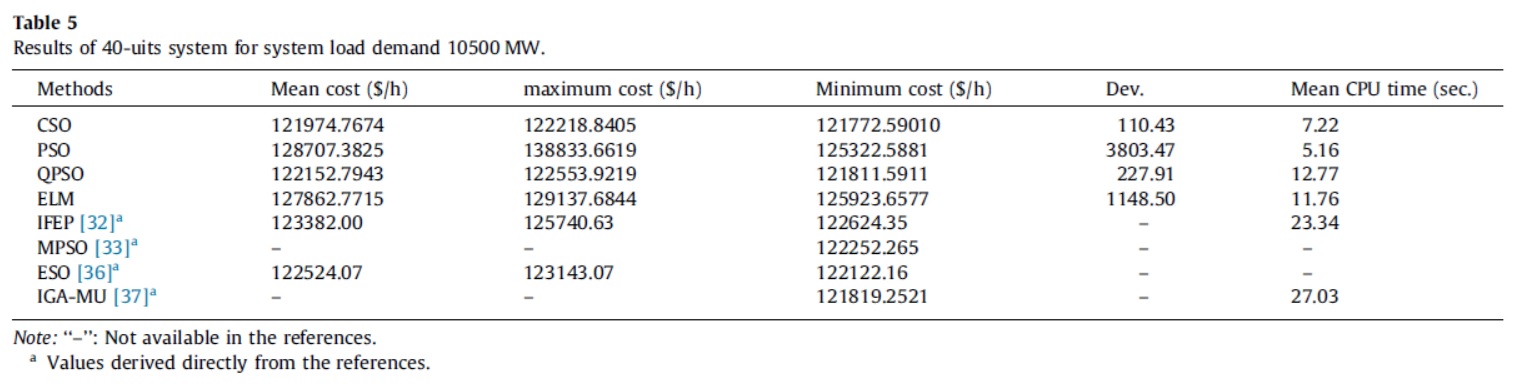
نکته پنجم: بر خلاف تصور نادرست که الگوریتم پیشنهادی را می توان فقط با مراجعی که اطلاعات کامل و تمام پارامترهای مورد ارزیابی مقاله ما را باید داشته باشد، میتوان برای مقایسه الگوریتم پیشنهادی از رفرنسهایی برای مقایسه استفادهکرد که فقط برخی از پارامترهای مورد ارزیابی در آن مشترک باشد. به طور مثال در Table 5 مرجع [5] این مورد نشاندادهشدهاست.
منابع
[1] http://cdn.persiangig.com/download/LrFom4rRvs/1-10.1016_s0167-6377(97)00004-7_z1ga.pdf/dl
[2] http://cdn.persiangig.com/download/YKTDRxDh71/2-1-vicaxcon-wilcoxon.s-plus.pdf/dl
[3] http://cdn.persiangig.com/download/AuckMQfOt9/3-1-Divercity-Relation3-download.pdf/dl
[5] http://cdn.persiangig.com/download/xPmljAcwup/5-SCIKnowledge-BasedSystems.pdf/dl